TL;DR; read the Octopus guidance, adopt the “environment per tenant” approach, try to make your process consistent across tenants and use scoped variables to make steps re-usable, keep complexity out.
In my last couple of posts I’ve written about the various aspects involved with automating the release of our client integration projects. I’ve shown how to get TeamCity to build Integration Services projects and then how to deploy them into SQL Server SSIS Catalog with Octopus Deploy.
In this post I’m going to explain how we setup Octopus Deploy for distributed multi-tenanted deployments.
What is a distributed multi-tenanted deployment?
A tenant in the context of DrDoctor it is a hospital. As mentioned in a previous post, when DrDoctor starts working with a new hospital we do some bespoke integration work to integrate their PAS system with our system. This ETL process is made up of a couple of staging databases and some SSIS packages which orchestrate the ETL process.
For each hospital that we work with, we are given a virtual machine within their network to which we deploy a database and a set of SSIS packages. We then have a schedule job that:
- Performs an ETL process on the client machine to transform the data from their PAS system into our schema
- Transfers the transformed data from the client site to our central database running in our data center.
So in our context we have a mixed deployment topology, some components go to a virtual machine running in a remote data center and some components go to our servers running in another data center.
Setting up Octopus Deploy
Octopus Deploy already has some very helpful guidance around different ways that it can be set up to support multi-tenanted deployments. There are broadly speaking two approaches: environment per tenant or project per tenant.
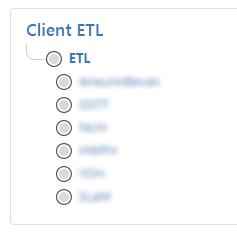
The process which I opted for was environment per tenant, in this approach there is a single project which contains all the different steps and variables, and multiple environments which represent the various tenants.
The reason I opted for environment per tenant is that our release process is the same for each of our clients, this keep the overhead of maintenance low and the process of setting up a new client easy.
setting up the environments
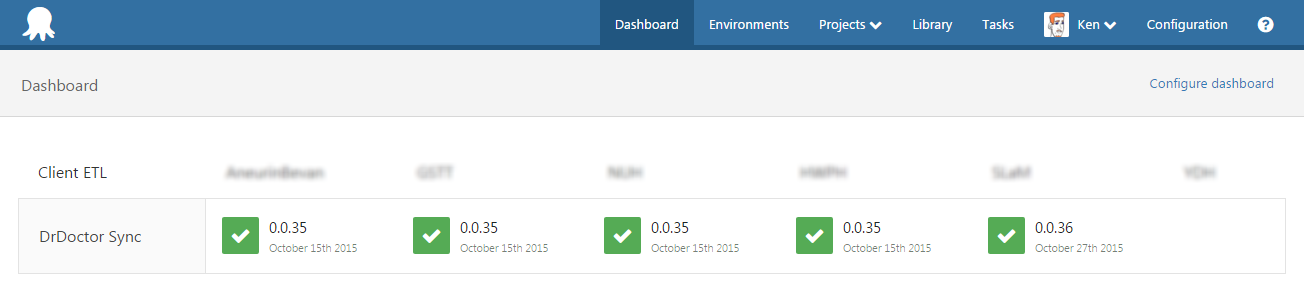
As per the Octopus guidance (linked to above) I created an environment for each of the hospitals DrDoctor currently works with. At this time they are all configured with an offline package drop deployment target while we work with the various IT departments to get their firewalls to allow the Octopus tentacles to communicate with our Octopus server.
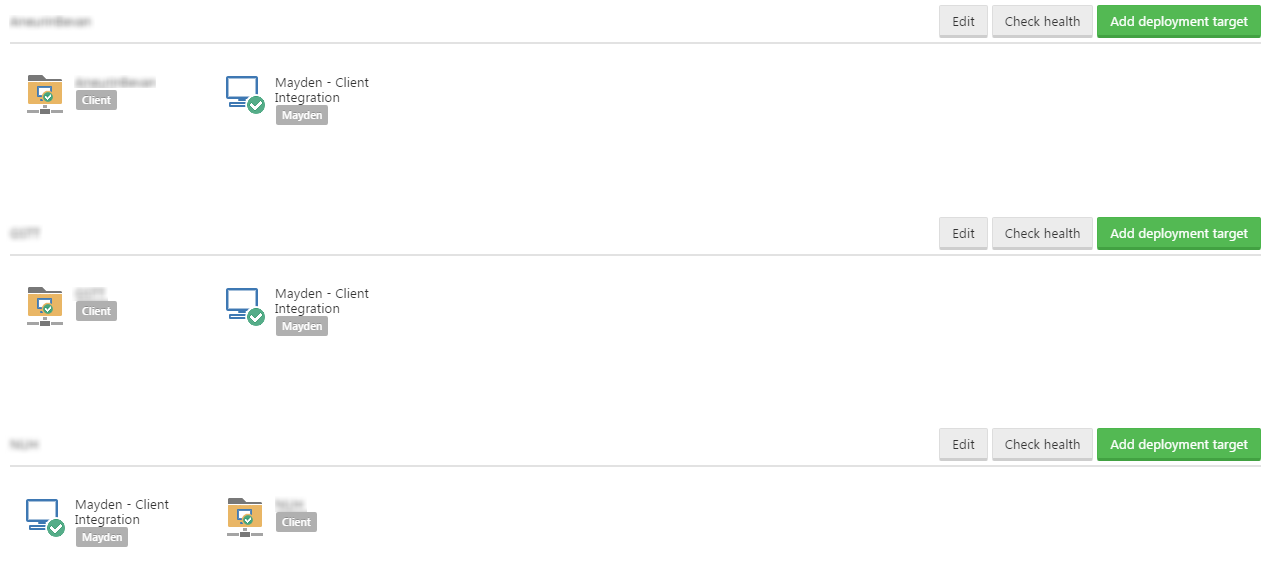
I also added to each environment a listening tentacle deployment target for the tentacle inside our data center, this the same tentacle but with multiple environments applied to it.

I also created a new release life cycle for this project, which treats all the environments as equals.
The release process
This is the release process at time of writing.
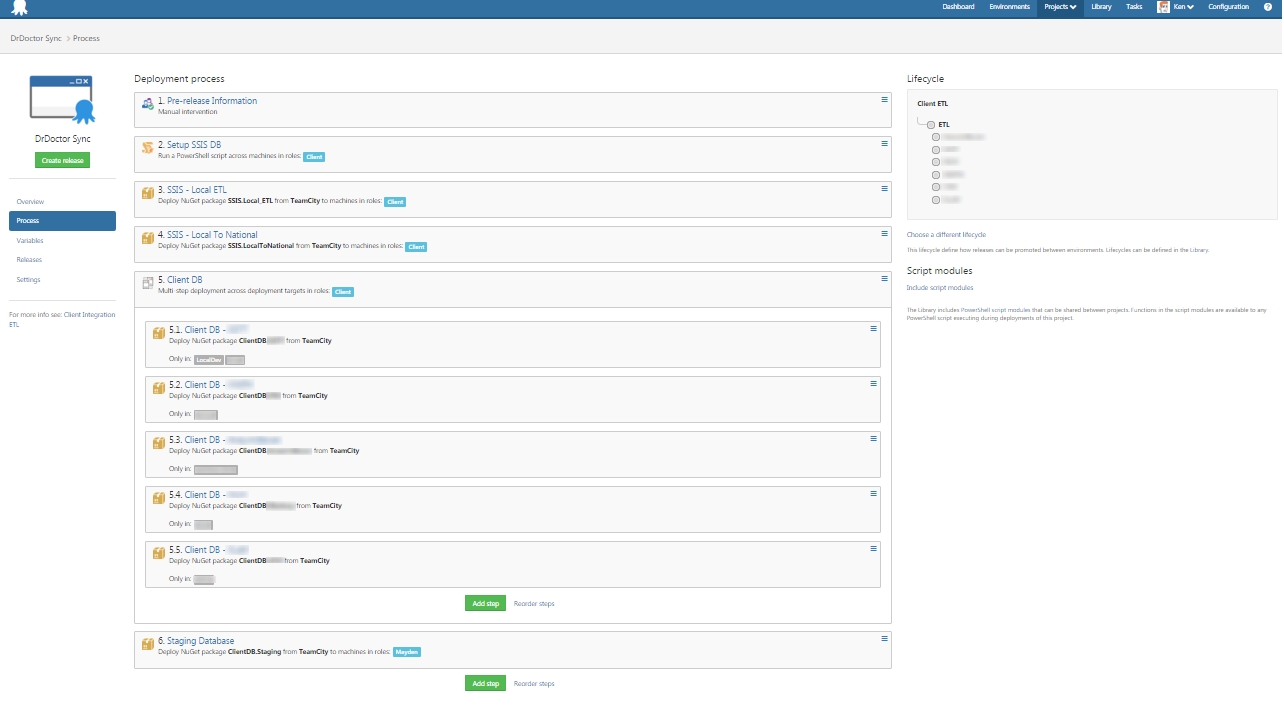 Steps 2-4 and 6 I covered in my previous post about deploying SSIS projects with PowerShell and Octopus Deploy. All of these steps make use of environment specific variables so they will work uniformly across all of our clients.
Steps 2-4 and 6 I covered in my previous post about deploying SSIS projects with PowerShell and Octopus Deploy. All of these steps make use of environment specific variables so they will work uniformly across all of our clients.
The step that is interesting is actually step 5. As I noted above, we have to do bespoke integration work for each of our clients, this involves writing custom transforms (stored procedures) and having a different set of database tables to which we import data from and to.
In Visual Studio we have a SQL database project for each of our clients (Local.ClientX), with all the common objects in a referenced database project. The client specific database project contains the transform stored procedures, import tables and client specific data mappings.
Each of these database projects are built by TeamCity and turned into NuGet packages for Octopus Deploy.
In step 5 there is a step for each of our different clients, with each step being scoped to a specific environment. The actual work being done in each of the sub-steps are identical with the exception of the NuGet package which is being deployed.
Configuring step 5 was the only point where I felt that the functionality of Octopus Deploy was lacking elegance. It would be much nicer to have a single step which dynamically picked the correct NuGet package based on the environment variable.
That wasn’t possible as far as I could see, hence why step 5 has lots of duplication.
Roles
There are two roles:
- client role – this is for all steps that should be run on the client integration machine
- mayden role – this is for the steps that should be run on our central server
Using roles allow us to control where each of the steps are run.
Introducing Offline package drop
At time of writing we haven’t yet negotiated with the various IT departments to allow the tentacles to get through their firewalls. However, with the release of Octopus Deploy 3.x this is no longer a deal breaker thanks to a new feature called offline package drop.
This is one of a number of new deployment targets that have been added in version 3.x. When you deploy a release to an offline package drop the Octopus server will create a local directory for that release/environment and bundle up all the release artifacts (NuGet packages, PowerShell scripts etc) and create a handy script which can be run to deploy the release. This is the perfect feature where you can’t have either a listening or polling tentacle.
So the release process now becomes:
- Create a new release in Octopus
- Deploy the release to one or more environments
- Zip the deployment folder and copy to the client machine
- Execute the deployment script
Assuming everything worked the client is now on the latest release.
Multiple deployment targets
One of the great features about Octopus Deploy is how the environments can be configured. As I showed above, in our environments we two deployment targets each scoped to specific roles. This becomes really handy when trying to coordinate different steps across different machines.
In our scenario, the way it has been configured is to have all the client specific steps go to the offline package target, and the step for our central server will go to the listening tentacle and therefore be executed without any manual work by the person doing the deployment.
The other nice thing is that once our clients start opening their firewall we can swap out the offline package drop with a listening or polling tentacle and the release process will just work as is.
Thoughts and advice
One of the biggest problems I was trying to address with all this automation was fear or more specifically releasing is really hard…so I’ll avoid it as much as I can. Before we automated the process we would often over point user stories that involved making changes to our ETL process because releasing was so hard.
One of the consequences I believe that has come out of this is that we will as time goes in build confidence in releasing changes, and therefore more easily make changes. There are loads of things we would like to do to our ETL process to make the actually process more efficient, or refactor some of the data structures. My hope is that all those little things we’ll start doing because it’ll no longer be a big scary release.
The main advice I would give to someone looking to use Octopus Deploy for multi-tenanted releases is this: adopt the environment per tenant and only one project approach. This might mean a little bit of pain making everything uniform, but it will reduce your overhead and give you a much simpler process to reason about.
The more I use Octopus the more it shows itself to be extremely flexible and suited to many different scenarios, but at the same time it doesn’t have to be complicated, you could very easily have a simple project up and running in an afternoon.
Go forth and automate.

[…] recently been doing some work automating the release of our integration projects to our various clients, I was reviewing the work that had been done last week and noticed that there were a lot of […]
Great article! We have a similar process for doing Package Drops for on-premise client deployments. I’m wondering how your clients react to re-keying the variables each time? Or do you store the clients variables in your server? Our clients were opposed to us storing their variables in our server.
We have about 50 tenant variables, so we ended up building a small WinForms app that “remembers” the tenant variables (stores them in the registry) and then pulls them back up during upgrades. It works, but as we add more to the process the WinForms app is becoming more than I care to manage.
Hi Scott, We stored all variables on our Octopus Server