I’ve recently been doing some work automating the release of our integration projects to our various clients, I was reviewing the work that had been done last week and noticed that there were a lot of variables being defined. If we continued on this course as we added new clients we would end up adding between 3-5 new variables, multiple that by say 100 new clients and soon we would have an incredible amount of variables to deal with.
In our project we use Octopus environments to represent our different clients; you can see from the image below that we were defining a lot of different variables for each of our clients.
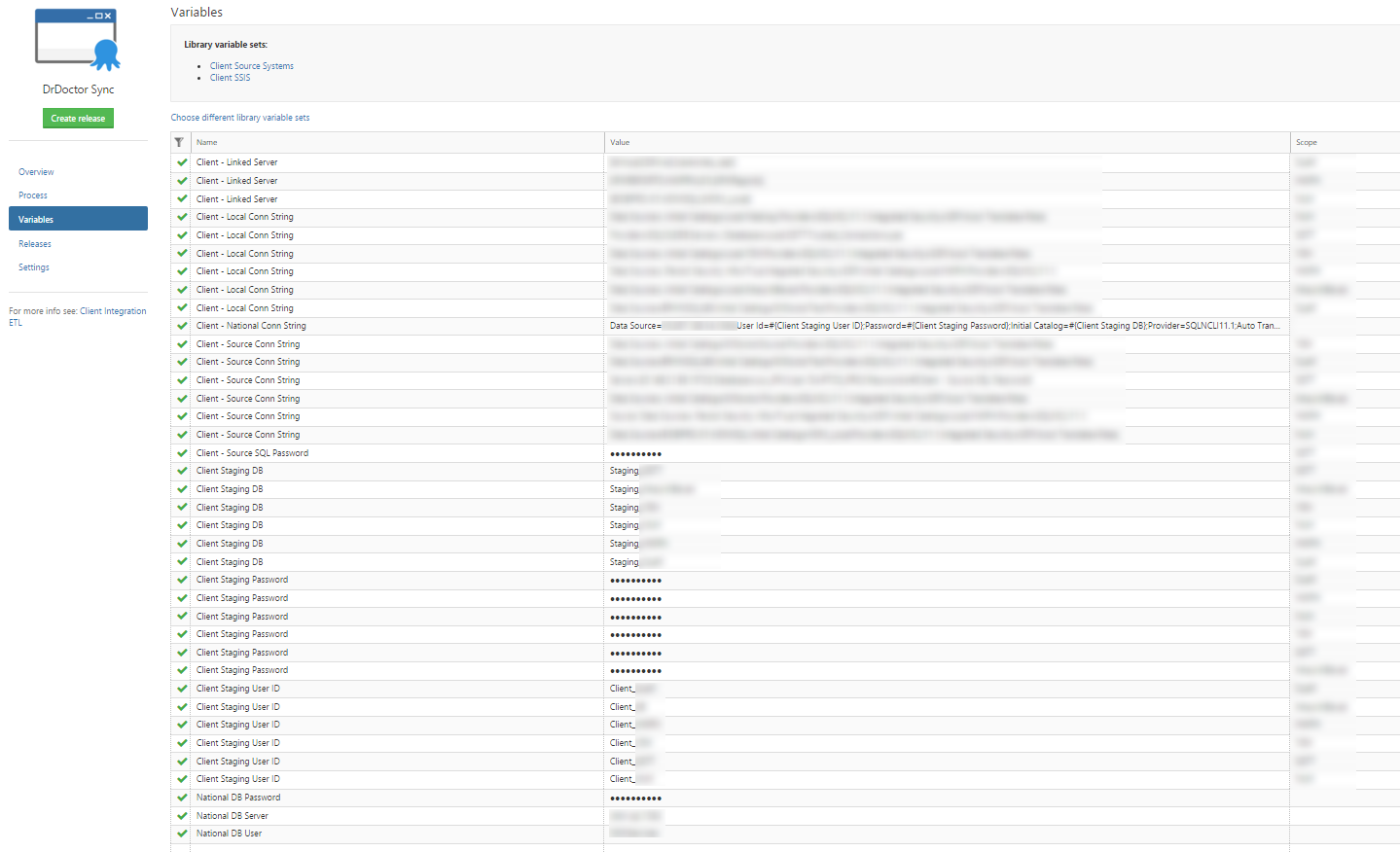
As you can see above with only a handful of clients it’s already getting out of control – there has to be a better way!
Embrace convention, simplify your life
Consistency by convention
It struck me that we had inadvertently created a few conventions in the way we were defining different variables.
For example we had the following variables defined for each of our environments:
- Client Staging DB, which represents the name of a database used by an ETL process these all took the form Client_[client name]
- Client Staging User ID which took the form Staging_[client name].
These two variables (along with Client Staging Password) are used in the Client – National Conn String variable.
It dawned on me that with a very simple convention I could get rid of most of these repeated variables.
So instead of continuing on creating scoped variables for each of our clients (environments) I embraced the Octopus Environment Name variable. Now all of these existing variables that were scoped to each environment have been deleted and now there is a single variable shared by all environments.
Client – National Conn String has been replaced with
Data Source=xyz;User Id=Client_#{Octopus.Environment.Name};Password=#{Client Staging Password};Initial Catalog=Staging_#{Octopus.Environment.Name};Provider=SQLNCLI11.1;
This means longer having to define the Client Staging DB and Client Staging User ID variables.
There were a bunch of other variables that I went through and updated to use the same convention. After making this change I went from having 38 variables, down to 22.
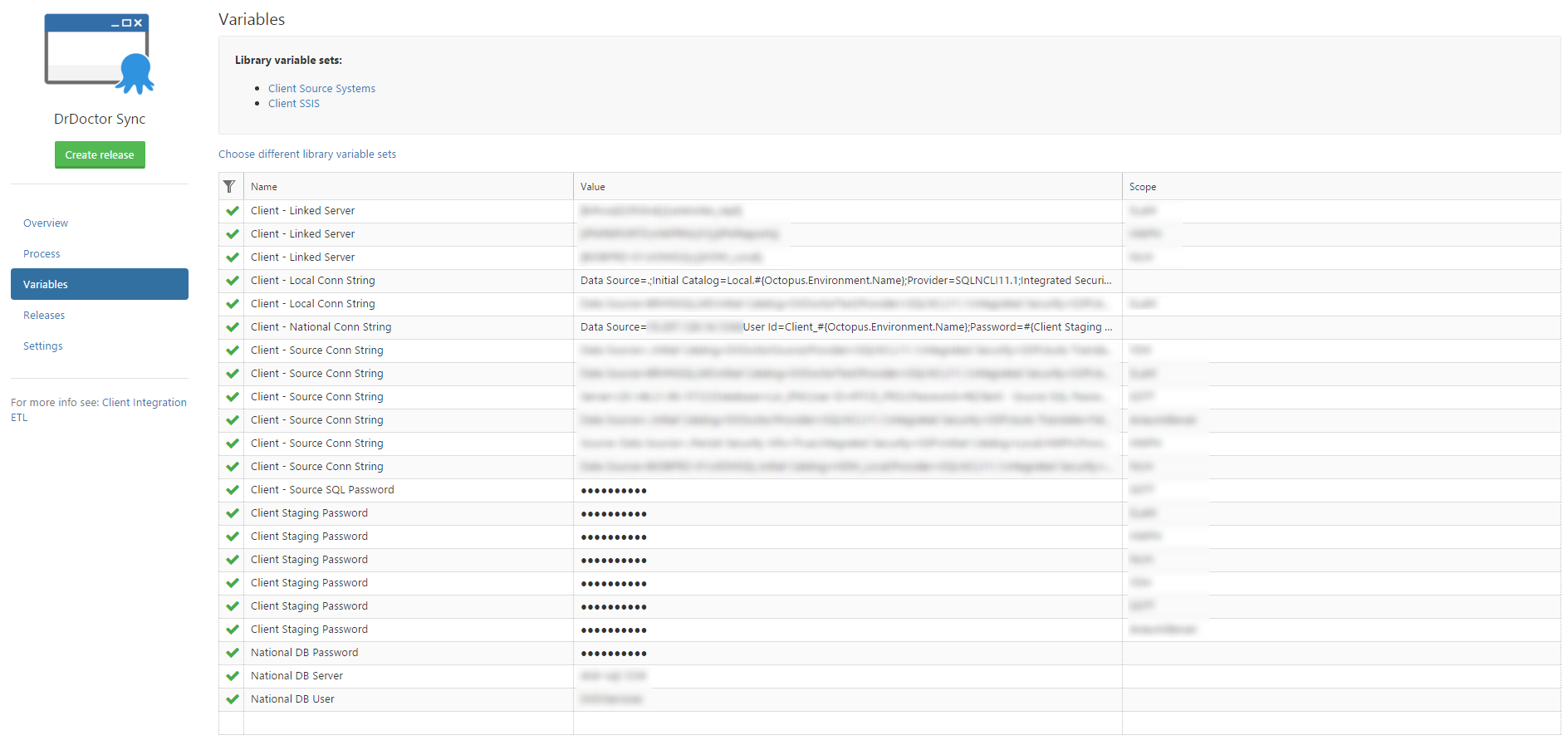
We now have an opinionated deployment process, which comes with some some big advantages:
- The process is easier to reason about
- Everything is consistent
- Less setup work when on-boarding new clients
But it’s good to be flexible
There is still room for exceptions, take the Client – Local Conn String variable, I was able to standardize this for all of our clients except for the one where we run our database on their cluster. For them I have a variable scoped just to their environment.
Octopus Deploy makes it easy to be flexible with variable scoping.
Variable sets reduce noise
The other trick that I’ve used is putting groups of related variables into their own variable sets. They are great for sharing variables between projects, but I’ve used them to remove noise from the project variables listing.
No pain no gain
It’s worth mentioning there was a little bit of pain, not all of the environments were configured consistently, not all of the SQL users were named according to the convention. Which meant a bit of manual work fixing things up; but in the long run it’ll pay off.
